ReView
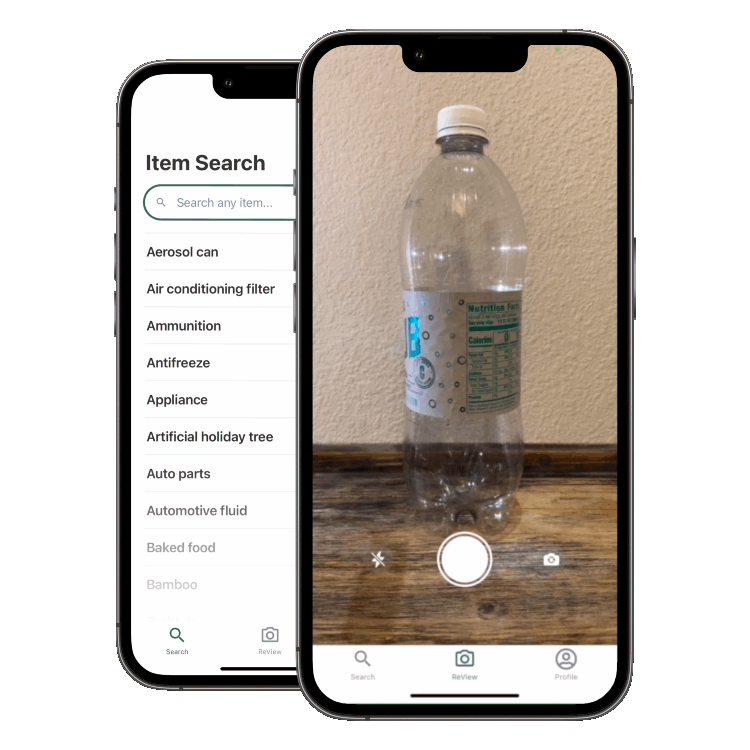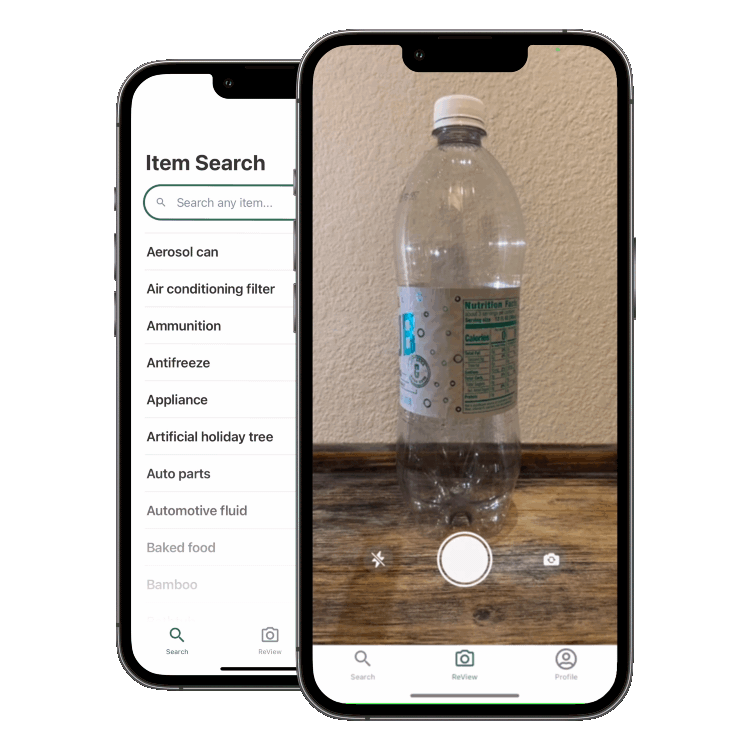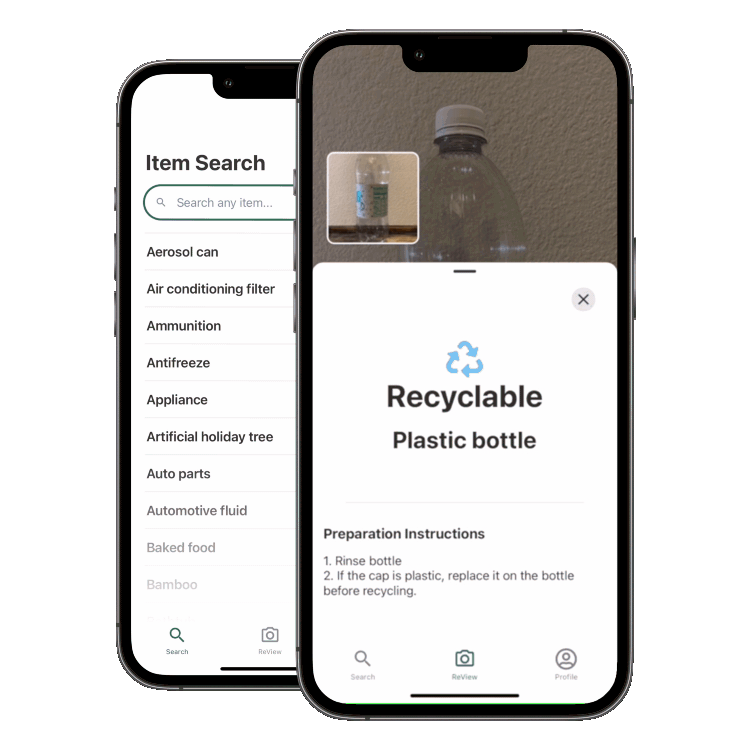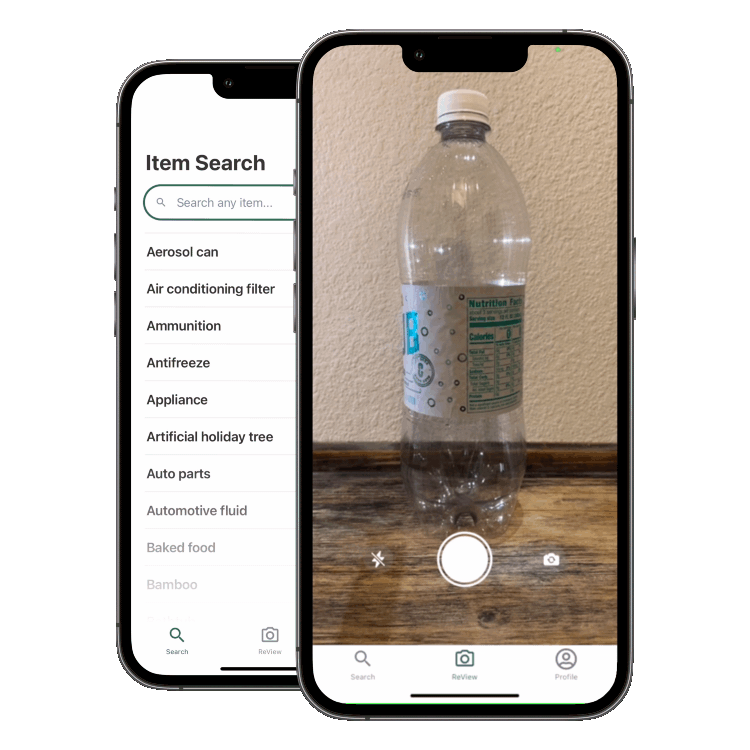
ReView is an app that allows users to learn what’s recyclable and compostable in their area by taking a photo of an item. The app uses a convolutional neural network to classify the item and a database of rules to determine if it’s recyclable or compostable. It’s built using a React Native/TypeScript frontend and a Firebase/AWS Sagemaker backend.
Autonomous MarioKart Ice Hockey Team
Deep Learning Assignment - UT Austin
November 2019 - December 2019
The Deep Learning final project tasked us with creating agents that could autonomously play 2v2 ice hockey against other teams in the class. The game took place within SuperPyTuxKart (an open source version of MarioKart). We used convolutional neural nets implemented in PyTorch to track the location of the puck and a custom controller to both score and defend. The custom controller operated as a state machine that leveraged the known player of the position and the visually-predicted location of the puck. Our grades were entirely based on how our team performed against other teams – we took 2nd place!

Autonomous MarioKart Racer
Deep Learning Assignment - UT Austin
October 2019 - November 2019
I created a driverless MarioKart! We were tasked with using a fully-connected, convolutional neural net in PyTorch to predict the location of a target driving point in PyTuxKart (an open source alternative to MarioKart). We were given gameplay images with circular labels on the correct driving point on the horizon, and we had to design and implement a convolutional neural net to predict the location of the ideal driving point while the game is being played. In other words, we built a model to predict where the kart should drive frame-by-frame. We also had to implement a custom controller to steer and accelerate the kart appropriately based on the location of your prediction. The video on the right shows my software predicting a driving point (the green circle) based on training from images labeled with the the ideal driving point (the red circle). My custom controller drives the kart to quickly follow my predicted ideal driving point. I think it’s ready for Rainbow Road!

16-bit MIPS Processor
Computer Architecture and Design - University of Virginia
January 2016 - May 2016
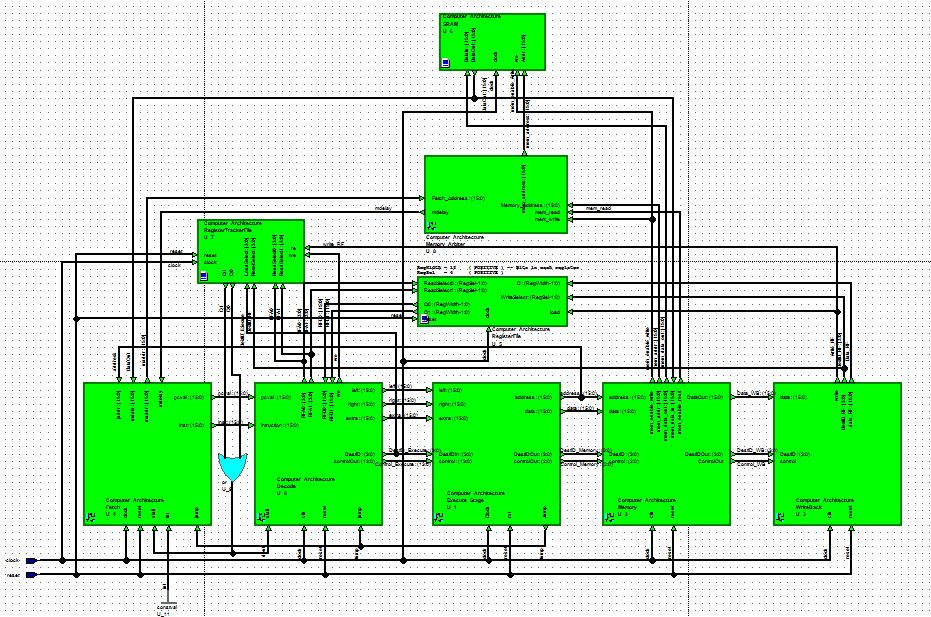
Computer Architecture and Design (ECE 4435) included a semester-long project that required implemented a MIPS processor in VHDL and run an assembly program on it (description below).
The processor included five stages: Fetch, Decode, Execute, Memory, and Writeback. The Fetch stage fetches instructions from memory and processes the program counter. The Decode stage decodes each instruction and passes on the control bits and components necessary for the instruction to be executed, which is done in the Execute stage. The Memory stage interfaces with memory and reads/writes if necessary. Lastly, the Writeback stage writes to one of the 16 general-purpose registers stored in the Register File. A Register Tracker was implemented to mark registers that are being written to or read from in future cycles and mitigate data hazards. A Memory Arbiter was used to mitigate structural hazards when it comes to reading/writing from memory.
Wizard's Chess
Senior Capstone Project - University of Virginia
August 2016 - December 2016
For our senior capstone design project, we were given the liberty of choosing our own design. All circuits had to be custom designed, and we only had three months to take it from concept to completion. Our group chose to design and implement “Wizards Chess” from Harry Potter (without piece destruction). When a player made a move, the circuit boards on each space detected the magnet on each piece. A microcontroller managed the game state and would communicate any changes to a laptop using the UART communication protocol. The laptop would hit the Stockfish chess API to compute the computer’s next move. We could vary the difficult of this algorithm via an integer parameter that varied from 1-100… no one could beat level 5! A motorized XY table received the move command from the microcontroller via the laptop and moved a magnetic arm in order to shift the computer’s physical pieces. The project drew upon our knowledge of software engineering, microcontroller programming, and circuit board design.

Meditation for Students - Founder
Student Organization - University of Virginia
May 2016 - May 2017
When I entered college in 2013, I was embarrassed to tell my new roommate that I would be meditating daily. Meditation was taboo at the time, but I found it to be a useful tool for stressing management and focusing in class. I founded a meditation organization to normalize it. By the end of the college, the org had hundreds of members and most people I knew had become practitioners.
